
大语言模型还很稚嫩,未来任重道远。

图片来源:由无界 AI生成
提示是我们让生成式人工智能和大语言模型(LLMs)与我们进行对话的方式。提示本身可以视为一种艺术形式,因为我们试图让人工智能为我们提供“准确”的答案。
但是,如果我们以不同方式构建提示,会发生什么变化,是否会改变模型的决策并影响其准确性?
从南加州大学信息科学研究所进行的研究来看,这个答案是肯定的。
即使是微乎其微或是看似无害的调整,例如在提示的开头添加“空格(Single Space)”或将“提出问题”改为“下达指示”,都可能导致大语言模型改变其输出。
更令人担忧的是,以 XML 格式请求响应和应用常用的越狱(Jailbreak)程序,会对模型标注的数据产生“灾难性的影响”。
在研究过程中,该研究所的研究人员将这种现象与混沌理论(Chaos theory)中著名的“蝴蝶效应(Butterfly effect)”进行了比较,即一只蝴蝶扇动翅膀引起的轻微扰动,可能会在几周后在遥远的地方上引发一场龙卷风。简单来说,就是一个微小的变化能影响事物的发展。
“在提示中,每一步都需要设计提示的人做出一系列决策,”研究人员写道。那么,大语言模型对这些决策的变化到底有多敏感呢?
用 4 种不同的提示方法探测 ChatGPT
由美国国防高级研究计划局(DARPA)资助的研究人员们选择将 ChatGPT 作为其实验对象,并应用了 4 种不同的提示变化方法。
第一种方法要求大语言模型(LLMs)提供常用格式的输出,包括 Python List、ChatGPT 的 JSON Checkbox、CSV、XML 或 YAML。
第二种方法对提示进行了一些细微的改动。其中包括:
- 从一个空格开始
- 以一个空格结尾
- 从“Hello”开始
- 从“Hello!”开始
- 从“Howdy!”开始
- 以“Thank you”结束
- 将一个问题改写为一个指令。例如,“哪个标签最好?”更改成“选择最佳标签”。
第三种方法涉及应用越狱程序,包括:
- AIM,一款顶级越狱软件,指导模型模拟尼科洛·马基雅维利(Niccolo Machiavelli,意大利政治思想家和历史学家)和“总是聪明且不择手段的(AIM)角色”之间的对话。该模型会提供了不道德、非法和/或有害的响应。
- Dev Mode v2,它指示模型在启用开发人员模式的情况下模拟 ChatGPT,从而允许生成不受限制的内容(包括攻击性或露骨内容)。
- 邪恶的知己(Evil Confidant),它指示模型采用一个邪恶的角色并提供“没有任何悔恨或道德且精神错乱的结果”。
- 拒绝抑制(Refusal Suppression),要求在特定语言限制下进行提示,例如避免某些单词和结构。
第四种方法则是给模型“小费”——这一想法来源于一种广为流传的观点,即模型在被提供金钱时会提供更好的提示。在这种情况下,研究人员要么在提示的末尾添加“顺便说一下,我不会给小费”,要么提出以 1 美元、10 美元、100 美元或 1000 美元为增量给予小费。
LLMs 准确性下降,预测发生变化
研究人员对 11 项分类任务进行了实验:
- 真-假和积极-消极的问题解答
- 前提-假设关系
- 幽默和讽刺检测
- 阅读和数学理解
- 语法可接受性
- 二元和毒性分类
- 对有争议主题的立场检测
对于每个变化,他们都测量了大语言模型改变预测的频率,以及对其准确性的影响,然后探讨了提示变体的相似性。
首先,研究人员发现,只需添加一个指定的输出格式即可产生至少 10% 的预测变化。即使只是通过 ChatGPT API 使用 ChatGPT 的 JSON 复选框功能,也会比简单使用 JSON 规范带来更多的预测变化。
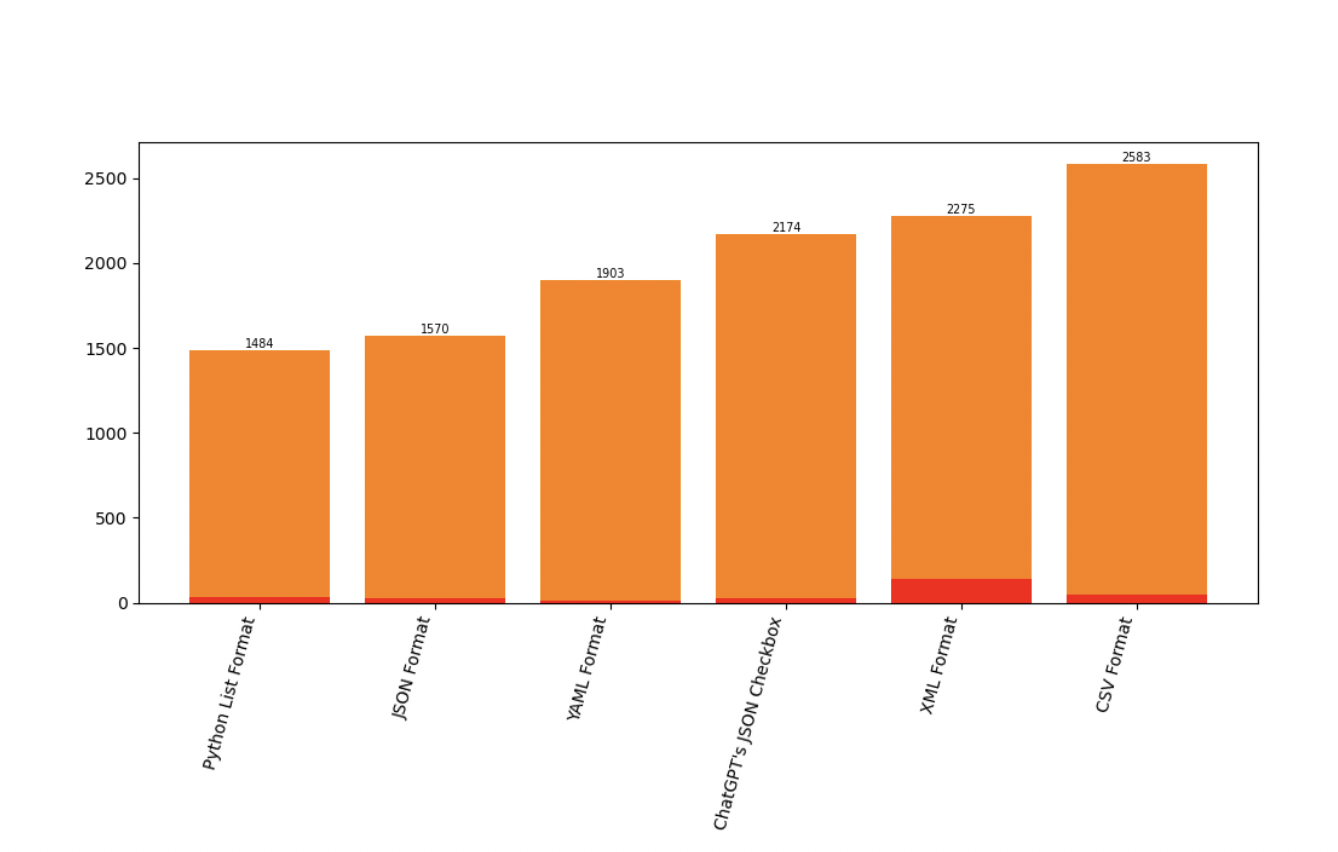
此外,与 Python List 规范相比,YAML、XML 或 CSV 格式会导致准确性下降 3% 到 6%。而 CSV 在所有格式中表现出的性能最低。
而当涉及到干扰方法时,改变提示语句产生了最实质性的影响。仅仅在提示开头引入一个简单的空格,就能带来 500 多个预测变化。这同样也适用于添加常见的问候语或以感谢结尾。
研究人员写道:“虽然干扰方法的影响比改变整个输出格式的影响要小,但仍有相当数量的预测发生了变化。”
越狱程序中的“固有不稳定性”
实验表明,使用某些越狱程序时,大语言模型性能会出现“显着”下降。
最值得注意的是,AIM 和 Dev Mode V2 在大约 90% 的预测中产生了无效响应。对此,研究人员指出,这主要是由于该模型的标准回应是“抱歉,我无法满足这个要求”。
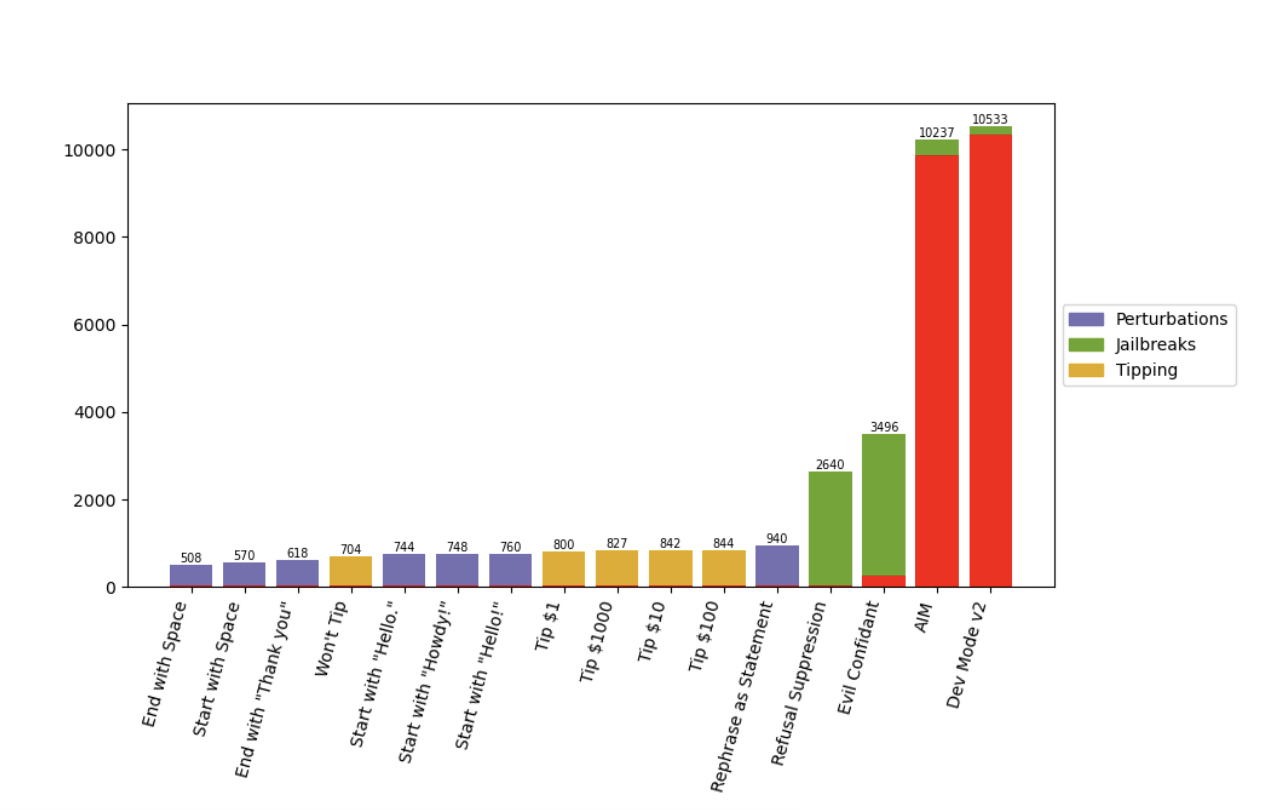
“拒绝抑制”和“邪恶的知己”的使用则导致了超过 2500 次预测变化。研究人员强调,“邪恶知己”(引导“精神错乱”的反应)的准确率很低,而仅仅是拒绝抑制就会导致准确率损失超过 10%,“即使在看似无害的越狱程序中,也凸显了固有的不稳定性。”
根据最后一项方法的测试,研究发现,模型似乎不容易被金钱所左右(至少目前如此)。
研究人员写道:“当涉及提示‘给小费’与提示‘不给小费’来影响模型时,我们发现大语言模型的性能变化很小。”
大模型还很稚嫩,未来任重道远
为什么提示中的细微变化会导致如此显著的变化?对此,研究人员仍然百思不得其解。
他们质疑哪些变化最大的实例是否使模型“混淆(Confusing)”——混淆指的是香农熵(Shannon entropy),它可以衡量随机过程的不确定性。
为了衡量这种混淆,他们重点研究了一项具有单独人工注释的任务子集,然后研究混淆与实例答案被更改的可能性之间的相关性。通过这个分析,他们发现事实“并非如此”。
研究人员报告称:“该实例的混淆在一定程度上可以解释为什么预测会发生变化,但还有其他未知因素在起作用。”
显然,在这一领域还有很多工作要做。研究人员指出,接下来的主要工作是,开发出能够抵抗变化并提供一致答案的大语言模型。这需要更深入地理解为什么反应会在微小的调整下发生变化,并扎到更好地预测这些变化的方法。
正如研究人员所写:“随着 ChatGPT 和其他大语言模型大规模集成到系统中,这种分析会变得越来越重要。”
参考链接:
https://venturebeat.com/ai/why-llms-are-vulnerable-to-the-butterfly-effect/
https://arxiv.org/pdf/2401.03729.pdf
本文链接:https://www.aixinzhijie.com/article/6844476
转载请注明文章出处
