
AI 新智界讯,1 月 5 日,“智求共赢・中国 AIGC 产业应用峰会暨无界 AI 生态合作伙伴大会”在杭州未来科技城召开。大会由杭州未来科技城管委会、余杭区科技局和余杭区企业(人才)综合服务中心联合指导,时戳科技主办,AI 新智界提供媒体特别支持。华为 EI 人工智能产品线副总裁李伟在会上围绕《昇腾云服务,服务百模千态——构建 AIGC 的黑土地》主题发表了演讲。
他表示,人工智能基础设施是新基建的核心任务,也是数字经济发展的基础设施。目前,大模型正推动 AI 从“作坊式”转向“工业化”。他强调,作坊式 AI 是不同场景对应不同小模型,分析数据给出建议,替代低端重复性工作物体识别和分析,但是小模型存在模型泛化的问题。工业化 AI 则是利用大模型吸收海量知识,适配多业务场景,并且解决了模型泛化性问题。另外,他还表示,算力已经成为新型生产力,打造对等的多元算力势在必行。

以下是 AI 新智界整理的演讲内容,为方便阅读已进行部分删减:
首先我先介绍一下自己。我们是华为云,内部叫作 EI。EI 包含了三部分内容:昇腾云服务,大模型以及大数据。大模型是盘古大模型,也包括开源大模型的能力适配。大数据在 AI 时代就是 AI for Data、Data for AI。其中昇腾云服务是把我们的大模型能力、AI 大数据能力全部沉淀到数字世界的统一载体。
在过去两年中,国家陆陆续续出台了一系列人工智能政策,从传统的数字化到智能化,不管是工信部、科技部,还是六部委、七部委。于企业而言,国家政策支持,是企业创业的一个前提条件。
为什么大模型会火起来?其实我们一直在做 AI。以前 AI 时代更多是一些小模型,比如视频监控,在一个场景里头识别物体、识别人,比如城市检测的垃圾识别有很多小场景,都由小模型完成。但是小模型有巨大的问题,就是模型泛化,在不同场景下解决模型泛化非常困难,场景一变,摄像头一变,模型和算法就要不断去适配。
在大模型时代,企业做到了知识能力的统一沉淀,泛化性问题得到了很好的解决。实际上,大模型时代是将人类知识做了很好的预训练,在预训练里做模型的微调。我们从最开始的模型到 Prompt、再到 Agent,一层层不断沉淀。这时候通过预训练的大模型,已经能够很好地解决多个场景用一个模型来适配,以及模型泛化性问题。

华为在去年 7 月的时候发布了盘古大模型。盘古大模型分为几个基础大模型,自然语言大模型、盘古大模态大模型、视觉大模型、预测大模型以及科学计算大模型。每一个大模型场景,都专注于解决一类的问题。通过五个大模型基础能力的研发和设置,我们又把它分成三层,称之为“5+N+X”,“5”就是我们的五个基模型,N 就是 L1 的行业模型,我们希望在每个行业里都能沉淀自己的行业大模型,同时针对行业大模型来构建每个行业的应用场景。
在这个过程中,从我们的实践经验来看,对于业界尤其是产业界而言,未来对基础模型这一块的投入研发非常具有挑战性。一个大模型本质上来讲是三个能力:一是数据,二是算力,三是模型。从模型来看,它是一个知识非常密集型的产业,同时它在算力上的需求非常巨大。根据 ChatGPT 公开的数据,训练一个基础模型,每次训练(例如 GPT-3.5)基本上都是 1200 多万美金,并且训练是不断迭代的,模型的参数将会越来越大。
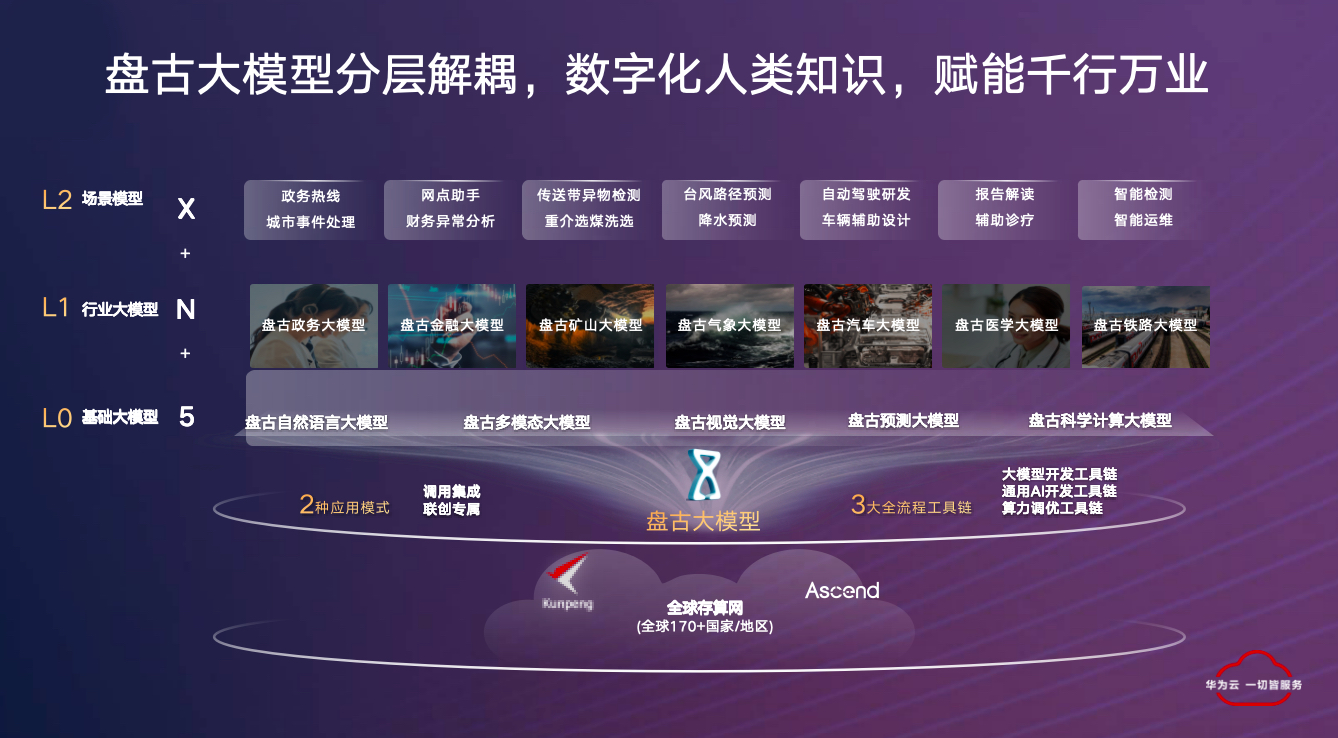
而数据获取并不是关键,获取到数据以后怎么样做数据清洗、数据治理才是关键所在。在行业中,每个行业将来都会有自己的行业模型出现,这就跟我们培养一个本科生一样,如果把大模型类比成一个学生,可能在某个场景中我们培养了一个本科生,但在将来一定会出现各个行业的研究生,各个场景的博士生,它们会专注去做一件事情,并且事情做到极致、做到最好。
从这一点来讲,L1、L2 这一块的架构同样是非常开放的,能够支持所有的合作伙伴、创业公司能在我们的盘古大模型和昇腾云服务上进行适配和开发。
在政务场景里头,华为抓住了政务服务、政务城市治理、政务办公等业务痛点。比如政务办公里头的文生图、文档摘要等业务痛点,整个视频监控里头的交通监控、城市危险识别、垃圾识别等等围绕城市治理的场景。在金融场景中,华为让每个员工都拥有专家助手,做到了复杂业务简单办理。我们认为,未来不管是面向政府也好,金融场景也好,本质还是要解决客户实际生产中遇到的痛点和问题,这样才能进行真正的商业闭环。
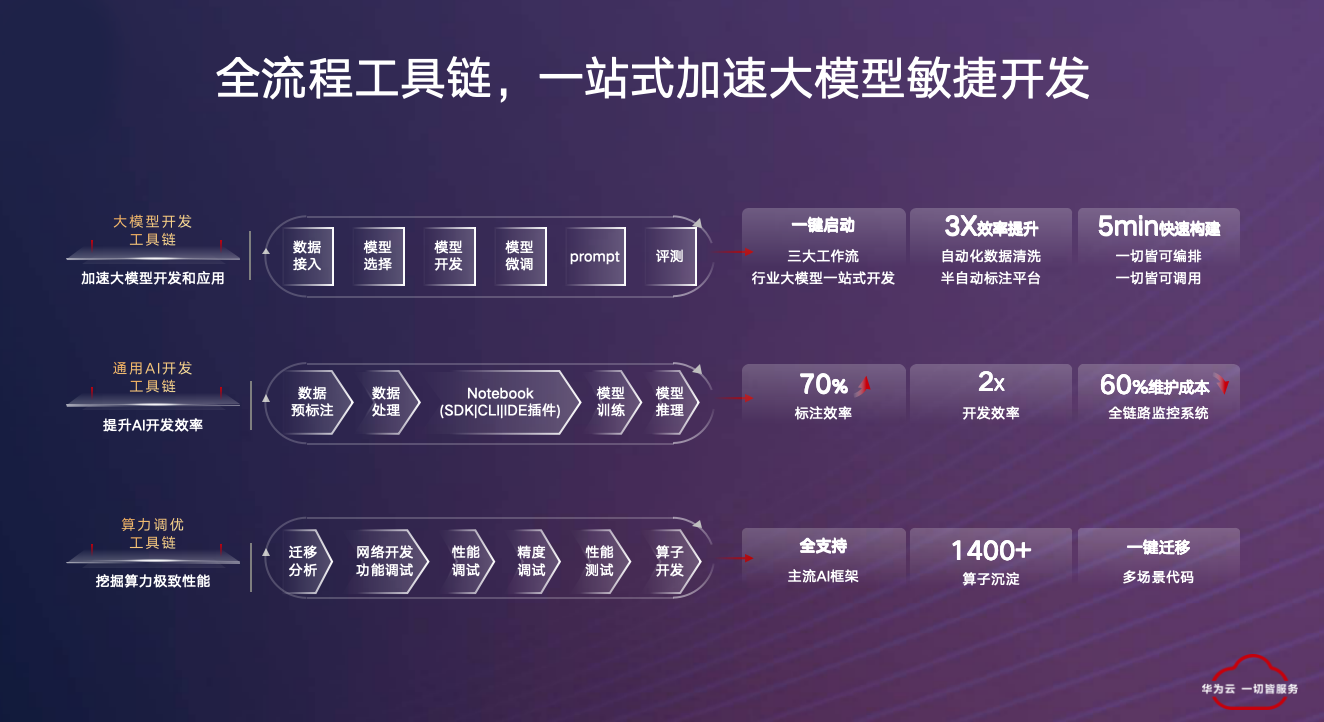
在做所有工作的过程中,华为也沉淀了非常多的能力。这些能力,一方面会沉淀到基础模型;另一方面,则会沉淀到工具链上。首先是围绕大模型的工具链。我们知道模型在训练过程中需要对数据进行治理和清洗,因此华为在数据工程方面积累了很多经验。同时,对模型方面有模型工程,不管你是做 Prompt 还是 SFT,还是做其他模型的调优,都需要基于模型的工程能力。
其次,在传统的 AI 能力上,华为也有通用 AI 开发工具链,包括数据预标注、数据处理、模型训练、模型推理。最后是算力调优工具链,背后的逻辑是算力连续性问题。现在业内真正卷大模型,不管是卷 NLP(专业分析人类语言的人工智能),还是卷 AIGC、卷文生图、图生文的大模型场景的时候,你会发现算力的问题一定是要长期考虑的。
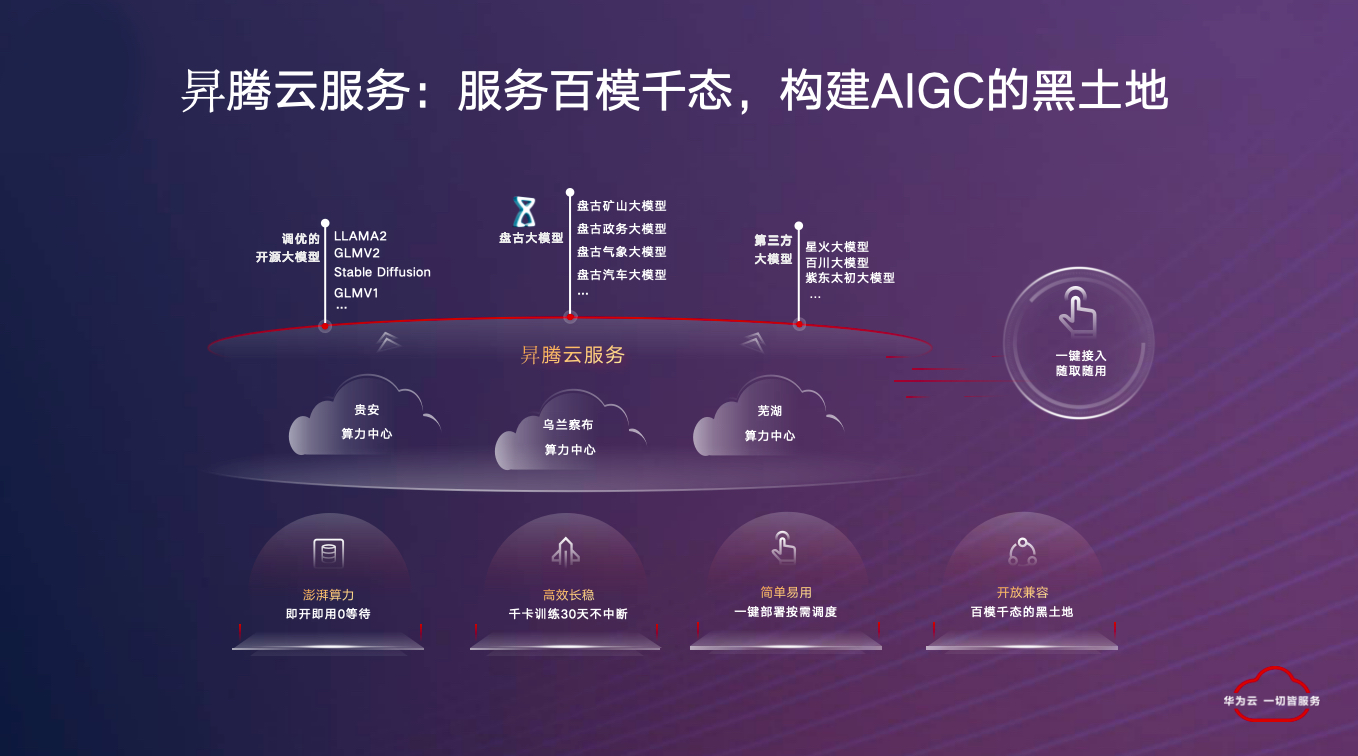
目前,业界主流的 AIGC 公司都已经在华为昇腾云服务上进行适配和调优。在此,我简单地将华为提供的工程能力、工具能力做了演示,主要是围绕模型开发,包括数据工程、模型开发、应用开发、测试,这些服务都在昇腾云服务上提供,并且支持公有云模式和私有云模式。
除此以外,我们提供昇腾云算力。例如,目前在贵安,华为已经建立了将近 7 万台以上的算力集群,将充足的算力提供给大模型各个厂家。另外,华为昇腾云还将工具和能力提供给所有的开源模型,并支持主流的开源模型,不管是开源模型的 LLaMA、GLM,还是多模态的 SD,还是第三方的星火、百川大模型。这么做能够帮助创业公司在昇腾云服务上快速构建其场景和能力。
而在数据层面,用户最关心的是数据的安全和保护的问题。在这个方面,华为对客户的数据安全隐私保护做到了极致。这体现在资源专属和数据主权上,包括数据在训练和推理过程中的保护。在整个全流程的可追溯、可控,以及专业化的安全方案上,华为都做了充足的准备和方案。
上述是我们承载的应用能力的展现。不管是开源模型,如 LLaMa、LLaMA 的 6B、7B、13B 等模型,还是其他的 GLM-6B 模型,昇腾云都会提供支持。
整体来讲,我们也希望所有的创业公司、所有伙伴都能够围绕开源模型,基于开源模型、盘古大模型,汇聚到昇腾云服务上。我们认为,华为未来 toC 场景一定会出现一些超级应用;对于 toB 场景,可能机会更多。
本文链接:https://www.aixinzhijie.com/article/6842892
转载请注明文章出处
