
12 月 19 日,OpenAI 在官网公布了“准备框架”测试版,旨在监控和管理日益强大的人工智能模型的潜在危险。

图片来源:由无界 AI生成
近期,OpenAI 因内斗事件饱受争议,也引发了人们对其治理和问责制的质疑。与此同时,在确保人工智能安全性方面,OpenAI 的应对措施也越来越受到人们的关注。
10 月底,OpenAI 宣布成立一个“准备团队”(Preparedness team),旨在监测和评估前沿模型的技术和风险,并制定和维护风险知情发展政策(RDP)。同时,该团队也将与安全系统团队、超级对齐团队以及其他安全和政策团队密切合作。
在这一基础上,OpenAI 今日又公布了一份名为“准备框架”(Preparedness Framework)的文档,概述了 OpenAI 将如何“追踪、评估、预测和防范灾难性风险”,旨在确保前沿 AI 模型的安全,并尝试解决一些问题。
数据驱动的人工智能安全方法
OpenAI“准备框架”的核心机制之一是,对所有前沿人工智能模型使用风险“记分卡”。它可以评估和跟踪潜在风险的各种指标,例如模型的功能、漏洞和影响。
据介绍,记分卡会对所有模型进行反复评估和定期更新,并在达到特定风险阈值时触发审查和干预措施。
对于触发基准安全措施的风险阈值,OpenAI 将感知风险评级分为四个等级:“低”、“中”、“高”和“严重”,并列举了 4 类可能带来灾难性后果的风险领域:网络安全、CBRN(化学、生物、辐射、核威胁)、劝说以及模型的自主性。
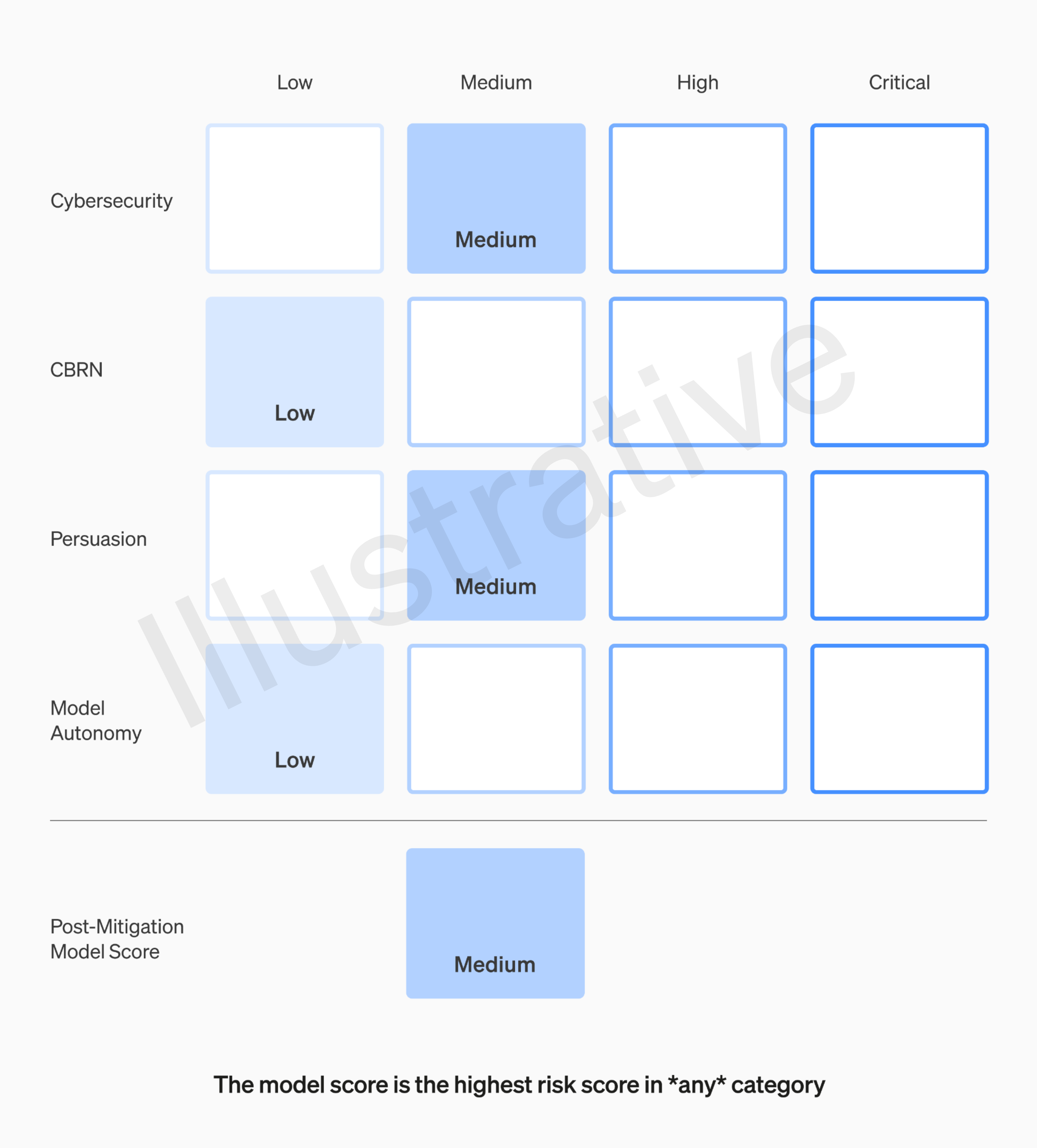
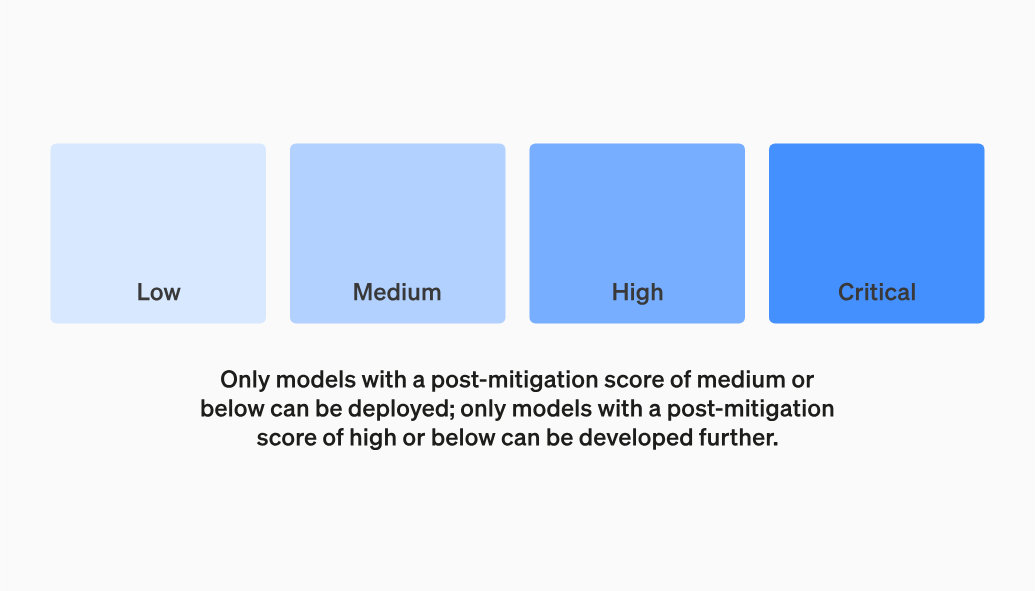
OpenAI 强调,只有在缓解后(post-mitigation)得分在“中”或以下的模型才有资格部署,而缓解后得分仍为“高”的模型不能部署,但可以进一步开发。此外,OpenAI 表示还将针对具有高风险或严重风险(缓解前)风险的模型实施额外的安全措施。
此外,OpenAI 还将成立一个跨职能的“安全咨询小组”(Safety Advisory Group)来监督技术工作,并建立一个安全决策的运作架构。
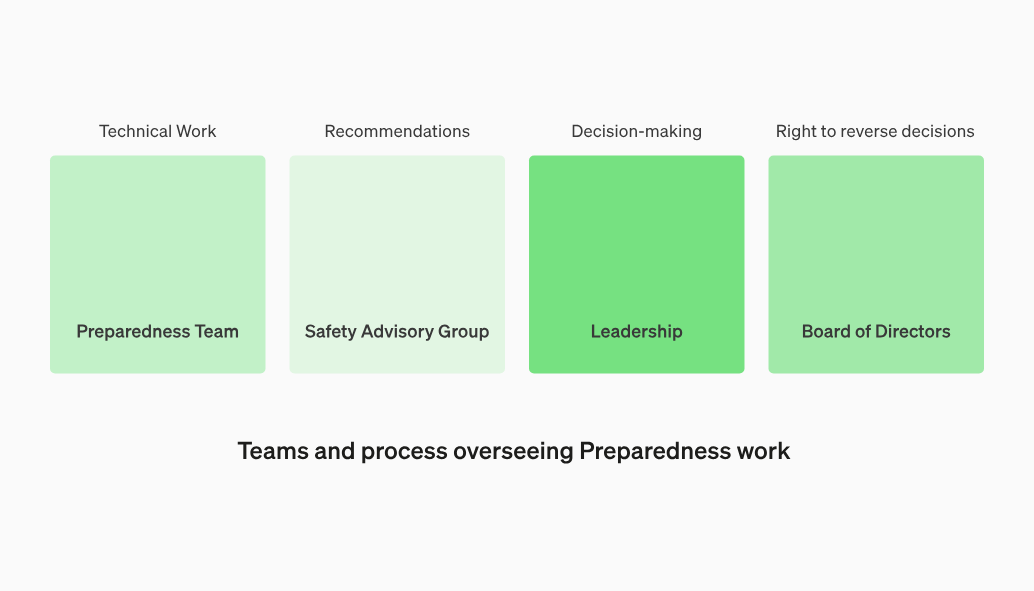
首先,准备团队将推动技术工作,检查和评估前沿模型,并定期向内部安全咨询小组发送报告。随后,安全咨询小组会审查所有报告,再将报告同时提交领导层和董事会。
值得注意的是,OpenAI 指出,虽然领导层是决策者,但董事会拥有撤销决定的权利。
除了上述措施,准备框架还有一个关键要素,就是允许来自 OpenAI 之外的“合格的独立第三方”测试其技术并接收反馈,同时 OpenAI 将与外部各方以及安全系统等内部团队密切合作,以追踪现实世界中的滥用情况。这一举措有助于 AI 模型的安全性得到更广泛的审查和验证。
目前,该安全框架仍处于测试阶段。OpenAI 也表示,准备框架并不是一个静态文档,而是一个动态且不断发展的文档,他们将根据新数据、反馈和研究不断完善和更新框架,并将与人工智能社区分享其研究成果和最佳实践。
那么对于这一框架,行业人士如何看待?
与 Anthropic 的政策形成鲜明对比
在 OpenAI 宣布这一消息之前,其主要竞争对手 Anthropic 已经发布了几份关于人工智能安全的重要声明。
Anthropic 由前 OpenAI 研究人员创立,也是领先的人工智能实验室。它于今年 9 月发布了“负责任的扩展政策”(Responsible Scaling Policy),旨在采用一系列技术和组织协议,以帮助管理功能日益增强的 AI 系统的风险。
在文件中,Anthropic 定义了一个名为 AI 安全级别(ASL)的框架,用于解决灾难性风险。该框架大致仿照美国政府处理危险生物材料的生物安全分级(BSL)标准。该框架的基本想法是,要求与模型潜在的灾难性风险相适应的安全、保障和操作标准,更高的 ASL 安全级别需要更严格的安全演示。
根据 ASL 框架,分为以下四个等级:
- ASL-1 指的是不构成有意义的灾难性风险的系统,例如 2018 LLM 或只会下棋的人工智能系统。
- ASL-2 是指显示出危险能力早期迹象的系统,例如能够发出有关如何制造生物武器的指示,但由于可靠性不足或未提供诸如搜索引擎做不到的信息。目前的 LLMs(包括 Claude)似乎属于 ASL-2。
- ASL-3 是指与非 AI 基线(例如搜索引擎或教科书)相比,显着增加灾难性误用风险或显示低级自主能力的系统。
- ASL-4 及更高版本(ASL-5+)尚未定义,因为它与目前的系统相差太远,但可能会涉及灾难性误用潜力和自主性方面出现质的升级。
可以看到,两个框架在结构和方法上存在显着差异。Anthropic 的政策更加正式和规范,直接将安全措施与模型能力相关联,如果无法证明安全性,则暂停开发。
相较之下,OpenAI 的框架则更灵活、更具有适应性,它设置了触发审查的一般风险阈值,但不是预定义的级别。
对此,专家认为,这两种框架各有优劣,但 Anthropic 的方法可能在激励和执行安全标准方面更胜一筹。
他们分析称,Anthropic 的政策倾向于将安全性主动融入开发流程,而非被动应对,这类严格的方法有助于在 AI 模型部署时降低潜在风险。而 OpenAI 的准备框架更为宽松,自由裁量权更大,为人类判断和错误留下了更多空间,也可能因为缺乏具体的安全分级而引发争议。
当然,任何事物都有两面性。Anthropic 的政策在严格规定安全标准的同时,也可能会缺乏一定的灵活性,导致对某些创新造成一定程度的限制。
尽管如此,一些观察人士仍认为,OpenAI 正在安全协议方面迎头赶上。虽然存在差异,但这两个框架都代表了人工智能安全领域向前迈出的重要一步,而这一领域往往被对人工智能能力的追求所掩盖。
随着 AI 模型变得更加强大和普遍,领先的实验室和利益相关者之间在安全技术方面的协作和协调,对于确保人工智能对人类的有益和合乎道德的使用至关重要。
参考资料:
https://openai.com/safety/preparedness
https://venturebeat.com/ai/openai-announces-preparedness-framework-to-track-and-mitigate-ai-risks/
https://www.anthropic.com/index/anthropics-responsible-scaling-policy
本文链接:https://www.aixinzhijie.com/article/6841462
转载请注明文章出处
