
就在十几个小时前的晚上,皮衣教主黄仁勋,带着他的英伟达推出了堪称最强的AI芯片H200 Tensor Core GPU:算力不变,性能飙升,容量翻倍,带宽大涨。具体来说,跑70B的Llama 2,推理速度比H100快90%;跑175B的GPT-3,推理速度比H100快60%;首撘141GB HBM3e,是H100显存容量的约1.8倍;带宽4.8TB/s,是H100带宽的1.4倍;明年第二季度发货。
在当前算力荒的背景下,大科技公司们估计又要开始疯狂囤货了。不得不承认的一点,老黄和英伟达的节奏真的愈发可怕了。而且H100和H200还是互相兼容的,这意味着使用前代训练与推理大模型的企业,很快就可以无缝更换成最新的H200,只要买得到。

一、地表最强如何强?
H200支持英伟达自家的NVLink和NVSwitch高速互连,可支持超过1750亿参数规模大模型的训练和推理,相比于前代H100,H200的性能提升了60%到90%。英伟达高性能计算和超大规模数据中心业务副总裁Ian Buck(伊恩·巴克),对此表示:“要利用AIGC和高性能计算应用创造智能,就必须使用大型、快速的GPU显存,来高速高效地处理海量数据。借助H200这全球领先的AI计算平台,业界领先的端到端AI超算平台的速度会变得更快,一些世界上最重要的挑战,都可以被解决。”
此外H200也是首款内置全球最快内存HBM3e的GPU,拥有高达141GB的显存。按照英伟达官方的说法,在对GPT-3的推理表现中,H100的性能就比A100提高了11倍,H200的性能又比A100提高到了18倍。巴克还称,英伟达将在未来几个月内继续强化H100和H200的性能,预计明年发布的新一代旗舰AI芯片,基于Blakcwell架构的B100将继续突破性能与效率的极限,敬请期待。同时明年英伟达还会将H100的产量增加两倍,目标是生产二百多万块。
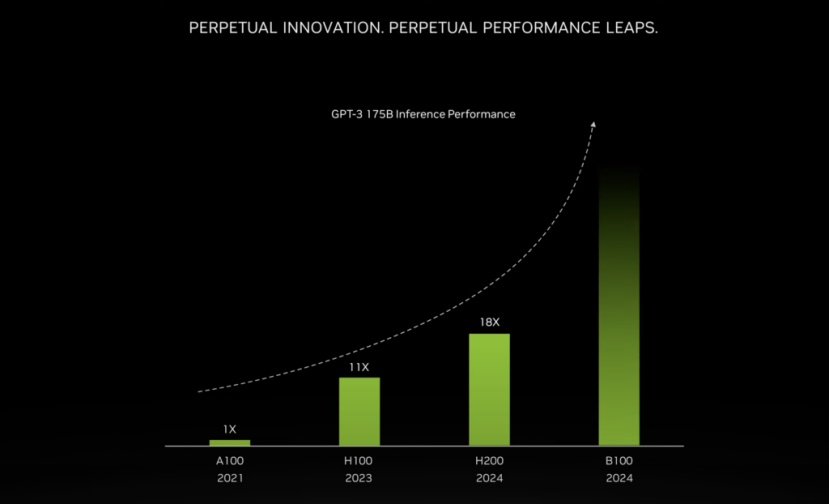
具体说来,对比前代,H200的提升最主要体现在大模型的推理性能表现上,在处理高性能计算的应用程序上也有20%以上的提升,而对于用户来说非常重要的推理能耗,H200直接减半。在这套组合拳的加持下,H200能大幅降低用户的使用成本,继续让用户“买的越多,省的越多”。如果说H100现在就是科技行业的“黄金”,那么英伟达这次是又成功制造了“铂金”。
二、超算界的军备竞赛
除了英伟达自己投资的CoreWeave、Lambda和Vultr之外,亚马逊云科技、谷歌云、微软Azure和甲骨文云基础设施,都即将成为首批部署基于H200实例的供应商。此外,在全新的H200加持下,GH200超级芯片也将为全球各地的超级计算中心提供总计约200 Exaflops的AI算力,用以推动科学创新。

多家顶级超算中心纷纷宣布,即将使用GH200系统构建自己的超级电脑。德国尤里希超级计算中心将在超算JUPITER中使用GH200超级芯片。这台超算将成为欧洲第一台超大规模的产品,是欧洲高性能计算联合项目(EuroHPC Joint Undertaking)的一部分。JUPITER总共拥有24000个GH200超级芯片,通过Quantum-2 Infiniband互联。每个Grace CPU包含288个Neoverse内核, JUPITER的CPU就有近700万个ARM核心。它能提供93 Exaflops的低精度AI算力和1 Exaflop的高精度(FP64)算力。这台超级电脑预计在明年安装完毕。

日本的先进高性能计算联合中心,由东京大学和筑波大学共同成立,也将在下一代超级电脑中采用GH200超级芯片构建。作为世界最大超算中心之一的德克萨斯高级计算中心,也将采用英伟达的GH200构建超级电脑Vista。位于伊利诺伊大学香槟分校的美国国家超级计算应用中心,将利用GH200超级芯片来构建他们的超级电脑DeltaAI,把AI计算能力提高两倍。此外,英国政府资助下的布里斯托大学正在负责建造英国最强大的超级电脑Isambard-AI,也将配备5000多颗GH200超级芯片,提供21 Exaflops的AI计算能力。此外,基于十月英伟达发布的TensorRT-LLM开源库,GH200超级芯片的速度是双插槽x86 CPU系统的110倍,能效是x86 CPU + H100 GPU服务器的近2倍。
在全球TOP 500超算榜中,得益于由之前H100 Tensor Core GPU提供支持的新系统,英伟达在这些系统中提供了超过2.5ExaFLOPS的HPC性能,相比五月排名中的1.6ExaFLOPS进步明显。同时新一期的全球TOP 500超算榜名单中包含了有史以来使用英伟达技术数量最多的系统为379个,而五月时的榜单中为372个,其中包括分布在全球各地的38台超级电脑。


这只是高校与研究组织间,如果算上AMD、英特尔等企业,那应该早已不再是军备竞赛,简直可说是白热化的了。面对英伟达这次的H200,老对手AMD的打算是,利用即将推出的大杀器Instinct MI300X来提升显存性能。MI300X将配备192GB的HBM3和5.2TB/s的显存带宽,这将使其在容量和带宽两方面超出H200一截。而英特尔也不可能闲着,计划提升Gaudi AI芯片的HBM容量,并表示明年推出的第三代Gaudi AI芯片将从上一代的96GB HBM2e增加到144GB。英特尔Max系列目前的HBM2容量最高为128GB,英特尔计划在未来几代产品中,还要增加Max系列芯片的容量。
三、围绕核心,剑指计算
距离去年搭载GPT-3.5的ChatGPT首秀即将过去一年,AIGC与大模型催生的大量加速计算需求仍然在不断增长,而且可能还将继续走高,对大模型的开发和部署带来的算力需求也成为许多企业的核心痛点,性能更强的AI芯片仍然是当下大模型企业竞争的重点领域之一。如今英伟达再次围绕着AIGC与大模型的开发和部署甩出了一系列硬件基础设施和软件工具,帮助企业突破大模型开发和部署的核心痛点,并且通过在数值、稀疏性、互联、内存带宽等方面的革新,不断巩固其在AI时代的霸主地位。赢麻了,老黄真的又赢麻了。
很多人现在最关心的问题是H200卖多少钱?英伟达暂时也还未公布。要知道,此前一块H100的售价就在2.5万美元到4万美元间,而要训练大模型至少需要数千块,所需的花费何止千万。此前一段时间,AIGC与大模型社区的一篇短文《我们需要多少GPU?》曾广为流传,并以图片的形式很快传遍各大社交网络的角落。虽然只是将一些企业训练自家大模型时的数据罗列出来,并对未来可能的发展趋势简单预测,但透过此也能看出外界对GPU这种稀缺资源的焦虑,管中窥豹可见一斑。“GPT-4大约是在10000-25000块A100上训练的;Meta需要大约21000块A100;Stability AI用了大概5000块A100;Falcon-40B的训练,用了384块A100。根据马斯克的说法,GPT-5可能需要30000-50000块H100。摩根士丹利则说是25000个GPU。”虽然OpenAI的CEO奥尔特曼否认公司正在训练GPT-5,但也说过“OpenAI的GPU严重短缺,使用我们产品的人越少越好。”

目前能知道的是,等到明年第二季度H200上市,届时必将引发新的风暴。科技网站The Verge表示,现在最关键的问题在于英伟达能否为市场提供足够的H200,或者它们是否会像H100一样在供应量上受到限制。而对这个问题,英伟达并没有给出明确的答案,只表示公司正在与“全球系统制造商和云服务提供商”合作来供应这些芯片,亚马逊、谷歌、微软和甲骨文等云服务商将是明年二季度首批使用H200的公司之一。从今年年初起,英伟达股价已经上涨了超230%,截至今天,其总市值已经达到1.2万亿美元。英伟达股价在H200发布后一度涨超490美元,最终报收于486.2美元,涨0.59%,盘后涨0.3%,股价实现九连涨。而且美国时间11月21日盘后,英伟达将发布今年第三财季财报。根据美国投资研究公司Zacks Investment Research的数据,预计调整后的每股收益(EPS)将达到3.01美元,而去年同期仅为0.34美元。
本文链接:https://www.aixinzhijie.com/article/6838396
转载请注明文章出处
